PPO (Proximal Policy Optimization)
개요
강화학습의 개요
- 환경 모델의 유무
- Model-based RL : 환경이 어떻게 변할지 예측하는 모델을 직접 학습하거나, 이미 알고 있음
- Model-free RL : 환경에 대한 예측 모델 없이, 실제 경험을 통해서만 학습 (PPO는 여기에 해당)
- 학습목표
- value-based : 어떤 상태에서 어떤 행동이 가장 높은 가치(Q값)를 가지는지 학습
- policy-based : 최고의 보상을 주는 행동의 확률을 직접 최적화
- Actor-Critic : Actor(정책)가 행동하고, Critic(가치)이 이를 평가하며 함께 학습 (PPO)
- 데이터 활용 방식
- on-policy : 현재 내가 가지고 있는 정책으로 직접 수집한 데이터만 학습, 데이터 효율이 낮지만 학습이 안정적 (PPO)
- off-policy : 과거의 나 혹은 다른 에이전트가 모은 데이터로도 학습이 가능, 데이터 효율이 좋지만 학습이 불안정함
Motivation
- policy 를 가능한 한 빠르게 향상시키되, 성능이 발산할 정도로 policy가 급격하게 바뀌는 것은 방지하는 절충안
구성 요소
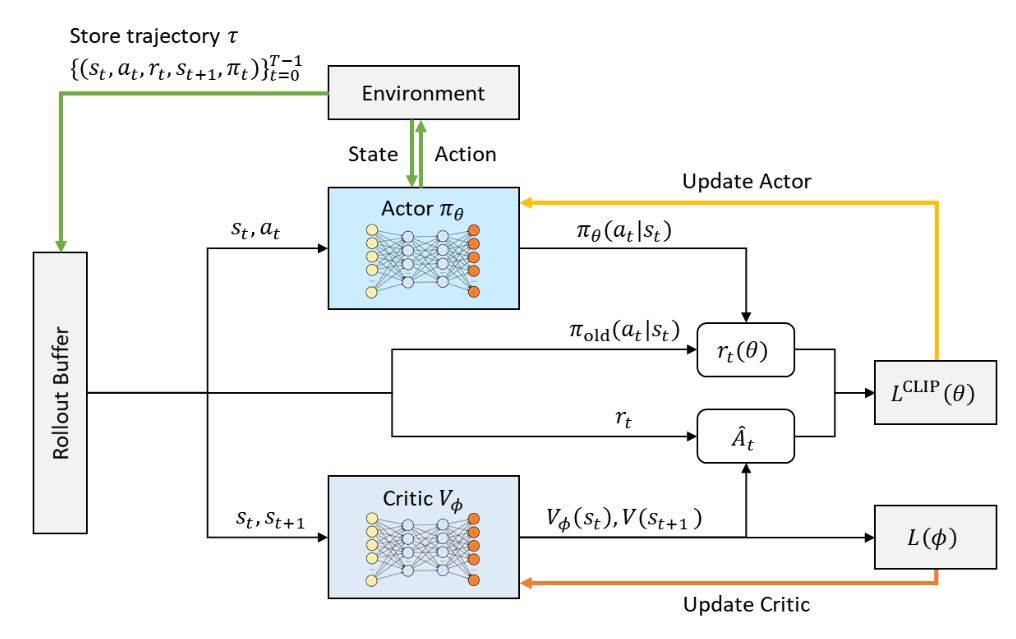
- Environment
- 물리엔진등의 휴머노이드와 상호작용하는 환경
- State
- 센서 데이터, 관측 데이터 등 환경에서 확인한 상태
- Action
- State에 대한 Actor의 반응 (모터 출력 등)
- trajectory (
) - 상태에 대한 Actor의 반응을 기록해놓은 벡터
- 병렬성 (ex. 4096) 과 에피소드의 길이 (혹은 중간에 끝날 경우 더 짧은 길이) 의 곱만큼 총 벡터가 존재하게 됨
- 해당 벡터를 미니배치 만큼 나누어 iteration, epoch 만큼 반복 (SGD)
: 상태와 action에 의해 변한 그 다음 상태 : 과 확률( ) 기반한 행동 : action에 대한 보상, 얼마나 훌륭한 행동을 했는지 보상함수를 거친 점수 : 에 대한 확률
- 상태에 대한 Actor의 반응을 기록해놓은 벡터
- Actor
- state 를 인풋으로 넣었을때,
와 를 반환하는 신경망을 담고있는 에이전트 - 해당 확률 분포에서 샘플링을 하여 action을 만들고, 그 샘플링의 확률을
로 함께 반환함
- state 를 인풋으로 넣었을때,
- Critic
- reward에 대한 baseline을 반환하는 에이전트
- critic이 예측한 것보다 더 좋은 reward가 나오면 서프라이즈로 그만큼 더 큰 adventage를 주고, 반대로는 낮은 adventage를 부여함
알고리즘
FW
- 환경에서 state 를 뽑아내어 Actor로 전달
- Actor는 action과 state, 그의 확률
를 반환 (이후 라 칭함) -
- 은 4096개의 로봇이 병렬처리됨, 2. 는 최대 에피소드의 길이 만큼 반복됨
- 3의 데이터를 이용해 셔플하여 학습에 사용 (시계열의 강결합을 막아, 오버피팅 방지)
Actor 업데이트
- iteration 동안
와 를 실시간으로 대입하여 얻어내는 확률을 로 칭함 - 위의 섹션에서 tranjectory 에 함께 담겨있던 확률을
로 칭함 - 두 확률의 비율인
를 구함. - 또한 Critic에서 나온
를 곱함 인 경우, 를 키우는 방향으로 업데이트, 즉 기존에 가 1이였다면, 즉, 현재 action이 발생할 확률을 키우는 식으로 신경망을 업데이트함 ( 이 1보다 커지게) 의 경우에는 반대로 작아지게 업데이트
- 최종 업데이트의 경우 Clipping 을 진행하여, 급격한 업데이트를 방지 (너무 급격한 보상 및 벌을 방지)
은 보통 0.2 로 잡아 [0.8, 1.2] 의 사이에서 업데이트 진행
Critic 업데이트
- t 시점과 t+1 시점의 state 를 대입하여, 게임이 끝날때까지 받을것으로 기대되는 총 보상의 합을 반환함
( , 둘다 critic의 반환값, 즉 현시점과 다음시점의 보상의 합의 곱) - Adventage 를 구함 (Appendix 참조)
- 첫 시점의
를 로 저장
- 최종적으로 도달해야할 가치를
로 간주함 - 손실함수
는 평균 제곱 오차 를 최소화하는 방향으로 신경망의 파라미터 를 조정함
Appendix
Adventage
오차 계산
- 각 타임스텝에서 TD Error를 구함
: 실제 보상 : 한 시점 뒤의 예측 보상 총합에 할인률 곱한것 (다음시점이라 0.99 정도를 곱함) : 현재 시점에서 예측한 보상
- 즉 현재 행동으로 얻은 보상 + 다음 상태의 가치가 현재 상태의 가치보다 얼마나 큰지를 나타냄
- 만약에 양수면
가 under valuation이고, 음수면 over valuation 이라고 볼 수 있음 - under valuation 이라는 것은
가 높다는 것이므로 예상치 못한 서프라이즈 상황, 좋은 상황이라고 볼 수 있음 ( 가 높은 상황) - 즉, 이 오차 델타가 > 0 이여야 좋은 상황임
- 이를 쓰는 이유는, 게임의 막바지에는 늘 좋은 상황임
- 이것이 내가 잘해서 좋은건지, 아니면 상황이 좋아서 좋은건지 판단하기 위함
- 만약에 양수면
GAE (General Advantage Estimation)
- GAE를 이용해 adventage 를 구함
(Lambda): 0과 1 사이의 하이퍼파라미터 이면 바로 다음 보상만 믿는 것 이면 에피소드 끝까지의 모든 보상을 다 믿는 방식
- PPO는 보통
정도를 사용하여 분산(Noise)은 낮추고 편향(Bias)은 적절히 유지하는 균형을 잡음 - 즉, 현재 시점에서 모든 시점의 "예상치 못한 이득"을 가중합으로 더해서 좋은 action인 나쁜 action인지 판단함
정리
- adventage는 좋은 환경, 나쁜 환경을 배제하고, 행위 자체에 집중하여 좋은 행위라면 높은 값, 나쁜 행위라면 음수값 (낮은값)을 가지는 변수