LSTM + Attention + 파라미터 역학관계
LSTM
! 700
- RNN의 장기기억의 한계, 즉 기울기 소실 및 폭등 문제를 구조적으로 해결하기 위해 등장하였음
- Input gate, forget gate, output gate 로 이루어짐
알고리즘
FW
-
Cell state
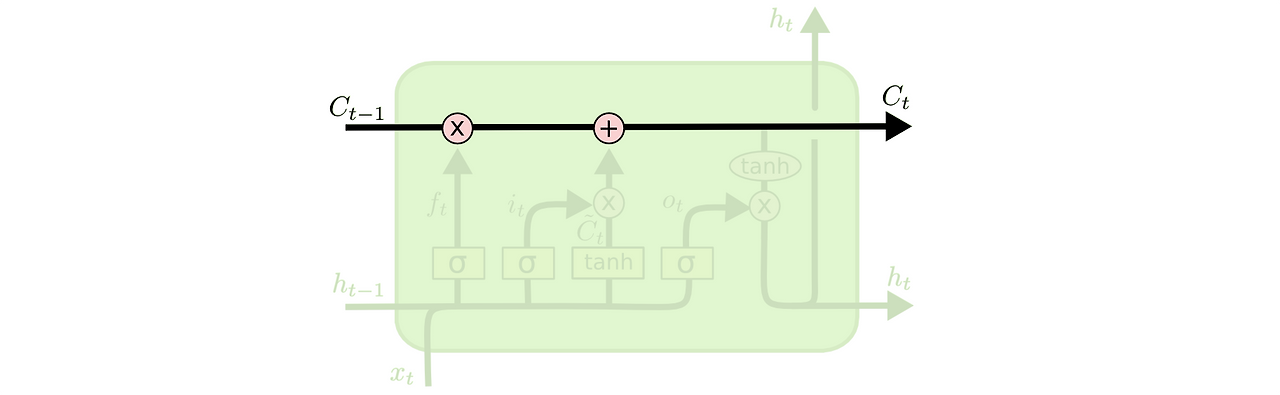
- 위의 그림과 같이 Cell state 를 유지하며 장기기억을 유지함
-
Forget gate
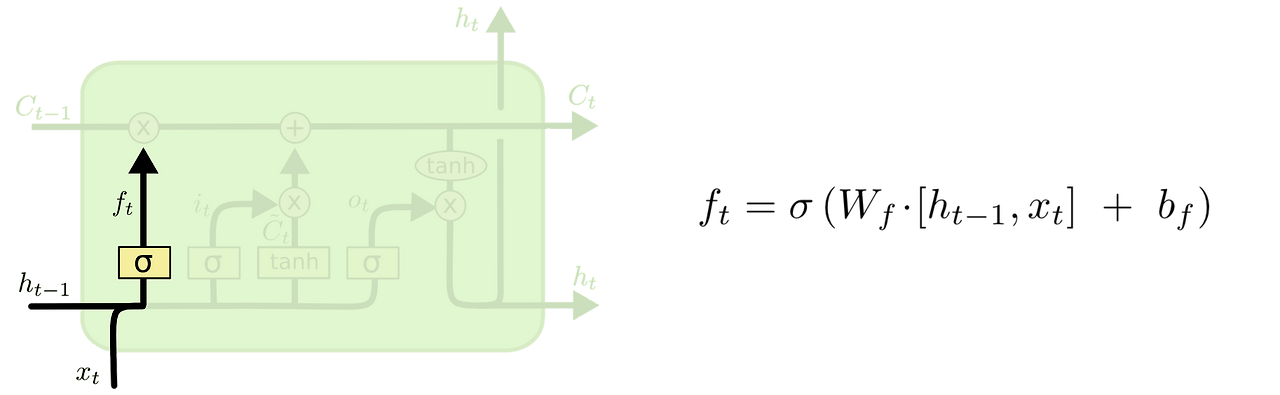
- 이전 시점의 Output과 현재 시점의 Input을 입력으로 받아 concat
- activation을 통해 vector를 0~1 사이의 vector로 바꾸고, 그를 장기기억과 곱해주어 특정 벡터는 1에 가까운 값을 곱해 유지하고 특정 벡터는 0에 가까운 값을 곱해 지우는 식으로 효율적인 장기기억 관리
-
Input gate
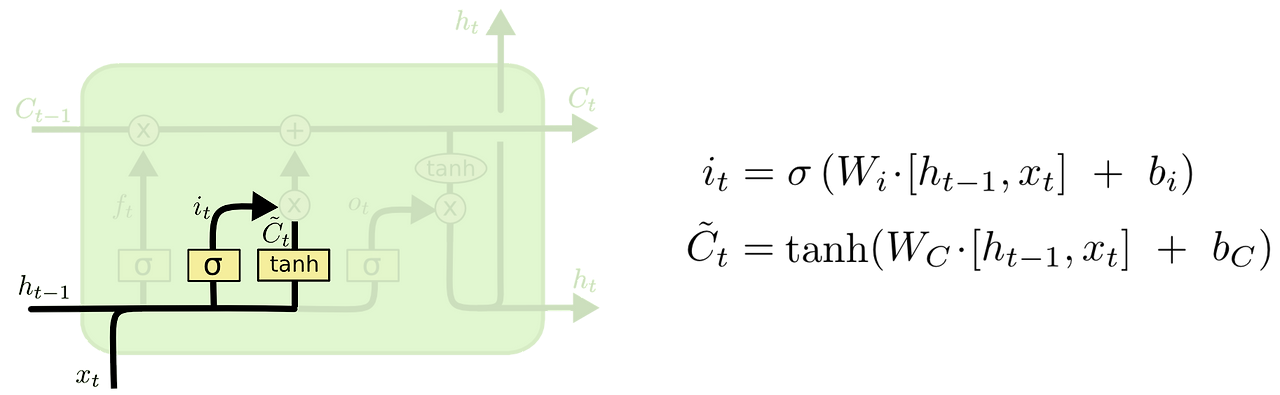
- 현재 시점의 데이터를 이전 시점 아웃풋과 concat
- activation 을 통해 어떤 것을 새로 기억할지 결정
- tanh 를 통해 들어온 입력을 비선형화
- 두 값을 곱하여, 장기기억에 기억할 내용을 효율적으로 저장
-
Forget과 Input의 조합
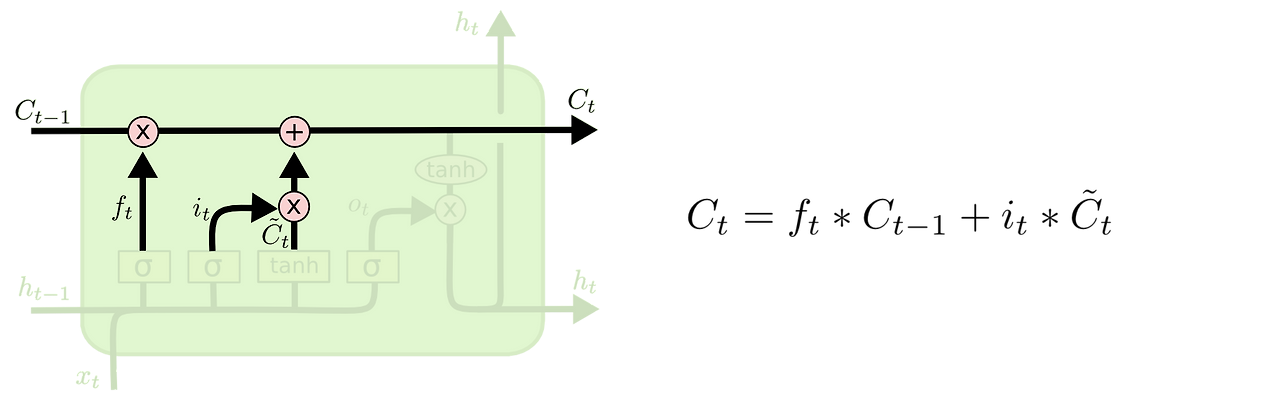
- 이전 장기기억에서 특정 내용 제거
- 현재 입력에서 어떤 것을 장기기억에 넣을지 결정
-
Output gate
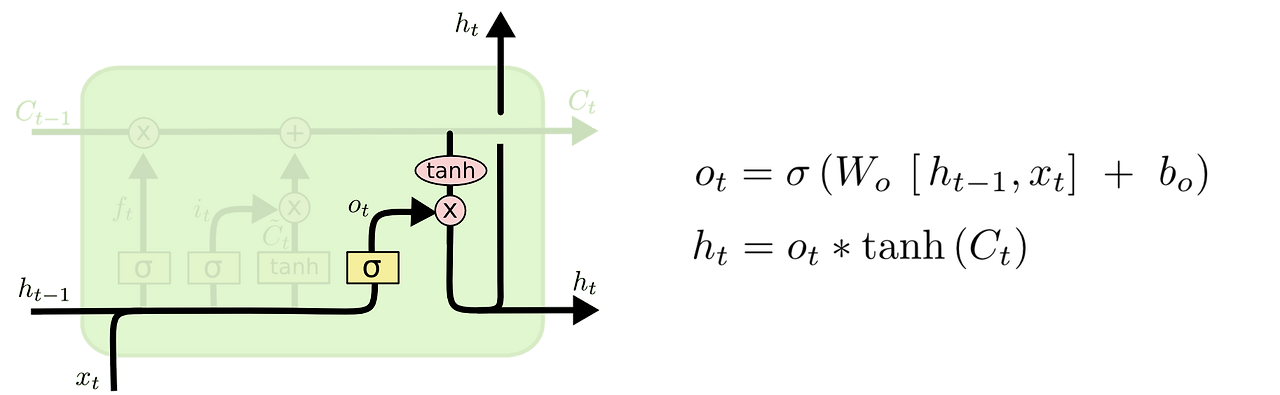
- 어떤 것을 단기기억으로 저장할지를 결정하는 activation
- 이전에 만든 장기기억을 tanh 로 비선형화를 하고 activation 한 값과 내적하여 원하는 내용만 단기기억으로 보냄
BW
- ANN의 기울기 업데이트
- 기울기는 정답과 나의 출력의 오차를 최소화하기 위한 방향으로 최적화된다.
- 오차를
라고 하고, 가중치를 라고 할때, 를 구하면, 가 최소화되는 방향을 알 수 있게 된다. - 최종적으로는
를 계산하여야한다. - 이는 chain rule을 통해 다음과 같이 구할 수 있다.
- 입력:
- 선형 결합:
- 활성화 함수:
- 최종 오차:
- 입력:
- RNN의 기울기 업데이트
- RNN도 위와 비슷하지만, 중간에 모든 시점의 의존성을 chain rule로 넣어줘야한다.
- 여기서 중간의 곱이 문제가 된다.
- tanh' 나 W가 조금만 작아도 0으로 수렴
- 반대로 크게 되면 기울기 발산
- LSTM의 기울기 업데이트
- LSTM은 h를 거치지 않고 C 만을 이용하여 기울기를 구할 수 있음
- 셀의 수식에서 이전 시점의 셀 (
) 로 미분을 진행 로 학습 초기부터 설정을 해놓으면 기울기 소실 없이 가중치 업데이트 가능
Attention
- 인공신경망의 꽃 Attention이다.
개요
- 어텐션은 원래 Seq2Seq의 고질적인 문제인 정보 병목을 해결하기위해 등장
- 긴 문장을 하나의 고정된 벡터로 밀어 넣다보니, 앞부분의 정보가 소실되는 문제가 있었음
- 디코더가 단어를 뱉을 때마다, 인코더의 모든 출력 중 관련있는 부분을 보두 확인하는 방식
- 이후에 이미지 처리, 시계열 예측 등에서 데이터 상관관계를 파악하는 표준으로 쓰이고 있음
핵심 매커니즘 (Q, K, V)
비유
| 요소 | 정의 | 비유 |
|---|---|---|
| Query (Q) | 영향을 주는 주체 (현재 찾고자 하는 정보) | 검색창에 입력한 검색어 |
| Key (K) | 영향을 받는 대상의 식별자 (데이터의 주소/특징) | 검색 결과물들의 제목/태그 |
| Value (V) | 데이터의 실제 내용 | 검색 결과의 상세 내용 |
알고리즘
- 유사도 계산: Query와 Key 사이의 유사도를 계산 (내적,
) - 정규화: 구한 유사도를 0~1 사이의 확률값으로 변환, 어텐션 가중치라고 부름
- 검색어와 검색 결과 제목들의 유사도를 계산한다고 비유가능
- 가장 연관된 검색 결과물에 더 많은 가중치가 높은 행렬이 나타남
- 최종값 산출: 어텐션 가중치에 정보를 내적함
가장 유사한 실제 내용(Value)이 더 많이 나오는 행렬이 나오게됨
Back propagation
- 일반적인 ANN과 같이, 체인룰 사용
use case
- COSuit 에서의 어텐션 풀링
- 시계열 윈도우 (30개의 벡터) 가 입력으로 들어오고, 어느시점이 가장 중요한 벡터인지 알고싶음
- 입력은 lstm의 결과물인(lstm_output으로 칭함) (batch_size, seq_len, hidden_dim)
- V: lstm_output, 즉 seq_len의 hidden_dim 중 무엇이 가장 중요한지 알고 싶음
- K: lstm_output, 우리가 알 수 있는 특징은 현재 lstm_output 밖에 없음
- Q: self.attn 즉 우리가 학습할 수 있는 가중치, 이를 통해 K에 대해 어떤 부분이 중요한 시점인지 Q가 학습을 하게 됨
파라미터 역학관계
마지막으로 학습시에 파라미터와 학습의 역학관계에 대해 설명한다.
학습률
- 가중치를 얼마나 업데이트할지를 결정
- 올리면: 학습 속도가 매우 빨라지지만, Global Minimum을 지나쳐 버리거나 오차 발산할 위험이 큼
- 내리면: 학습이 안정적으로 진행되지만, 너무 느려서 학습이 안끝나거나, 로컬 미니마에 빠질 수 있음
배치 사이즈
- 한 번에 몇 개의 데이터를 보고 가중치를 업데이트할지 결정
- 올리면
- 한 번에 많은 데이터를 보므로, 기울기가 매끄럽고 안정적임
- GPU의 병렬을 최대한 활용해 하드웨어 효율이 좋아짐
- VRAM의 점유율이 올라가고, 모델의 일반화 성능이 떨어질 수 있음
- 내리면
- 기울기에 노이즈가 섞여서 매 업데이트가 흔들림
- 학습시간이 길어짐
- 노이즈가 오히려 로컬 미니마를 탈출하게하는 regularization (규제, 일반화) 역할을 하기도함
- 올리면
모델 파라미터 크기
- 모델의 뇌 용량을 결정함
- 올리면
- 복잡한 데이터를 잘 기억함
- 데이터가 충분하지 않으면, 과적합이 발생
- 추론속도가 느려짐
- 내리면
- 모델이 가벼워지고 연산이 빠름
- 특징을 못담는 과소적합이 발생할 수 있음
- 올리면
드롭아웃
- 학습 중 일부 뉴런을 꺼버리는 강한 훈련 방식
- 올리면
- 특정 뉴런에 의존하는 현상을 막아, 적응력을 올림
- 너무 높으면 모델이 바보가 됨
- 내리면
- 훈련 데이터에 과적합이 발생할 가능성이 큼
- 올리면