검정(hypothesis testing)
- 가설검정의 필요성
- 콜레스테롤이 평균적으로 200mg/dl 이라고 하자
- 콜레스테롤 감소 캠페인을 진행하고, 1년뒤 50명을 대상으로 조사를 해봤는데 195mg/dl가 됐네
- 가능성 A: 캠페인은 효과가 없는데 50명 뽑은게 운이 좋아서, 낮아졌다.
- 가능성 B: 캠페인이 효과가 있어서 도시 전체의 평균이 낮아졌다.
- 가설검정은 A를 설명하기 위해 필요함
- 내가 본 데이터의 변화가 우연인지, 근거가 있는 변화인지 판별하는 필터가 필요기 때문에 필요함!
가설검정
- 모수에 대한 가설이 적합한지 추출한 표본으로 판단하는것
가설
- 귀무가설(
): 없다고 주장하는 가설 - 콜레스테롤 수치는 200mg/dl 이고, 과거 1년전과 차이가 없다.
- 대립가설(
): 있다고 주장하는 가설 - 콜레스테롤 수치는 200mg/dl 보다 작다. 즉 1년전보다 작다.
가설의 판정
- 연구자가 귀무가설
의 판정기준을 설정 - 기준은 상위 5%, 하위 5%, 상하위 2.5% 등으로 설정가능
유의수준
- "
보다 희귀한 확률을 진짜라고 믿을 것이다" 라고 생각하는 것과 그 수준 - cf) p-value: 귀무가설이 맞다고 가정했을때, 우연히 우리의 관측값이 나올 확률
- p-value가 유의수준보다 낮으면 귀무가설을 기각함
- cf) p-value: 귀무가설이 맞다고 가정했을때, 우연히 우리의 관측값이 나올 확률
- 유의수준과 임계값
- 유의수준보다 크거나 작게 하는 값의 지점을 임계값이라고 함
- 상위 5%
- 평균이 200mg/dl 이라고 가정했는데, 관측값이 207(예시)보다 크게 나올확률이 5%이다.
- 207보다 높다면, 우연히 높은게 아니고 귀무가설을 기각
- 하위 5%
- 평균이 200mg/dl 이라고 가정했는데, 관측값이 193.49(예시)보다 작게 나올확률이 5%이다.
- 193.49 낮다면, 우연히 낮은게 아니고 귀무가설을 기각
- 상하위 2.5%
- 평균이 200mg/dl 이라고 가정했는데, 관측값이 212보다 크거나 189보다 작다 -> 그러면 관측값이 우연히 다른게 아니고 귀무가설을 기각
가설에 대한 판정
| 실제/판정 | 기각 못함 | 기각 | |
|---|---|---|---|
| 참 | 옳은 결정 | 제 1종 오류 확률 | |
| 거짓 | 제 2종 오류 확률 | 옳은 결정 |
- 제 1종 오류 확률(type I error probability,
) : 귀무가설이 맞는데, 기각하는 확률 - 제 2종 오류 확률(type II error probability,
) : 귀무가설이 틀린데, 기각하지 않는 확률 - 검정력(power,
) : 대립가설이 옳을때, 대립가설이 옳다고 말할 확률
가설에 대한 판정에 대한 고찰
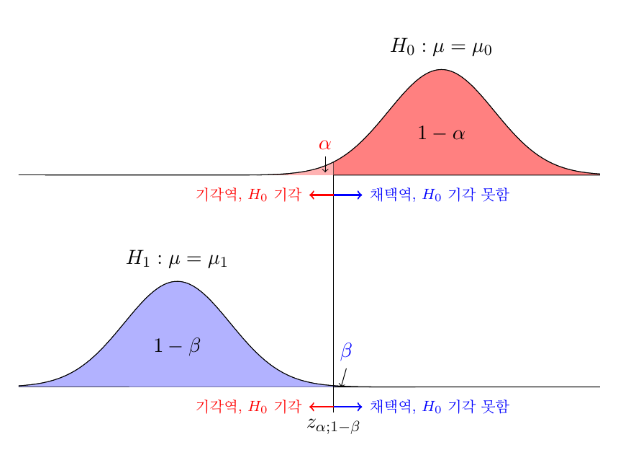
- 가설과 확률분포
- 제한된 표본에 의한 가설이므로,
와 은 확률분포를 따르게 됨 - 같은 데이터와 표준오차를 가짐으로 (
) 둘의 확률분포 모양은 정확하게 같음 (데이터가 많으면 z-분포, 적으면 t-분포) - 데이터가 많아질수록 오차가 적어져, 평균에 몰리는 형태의 홀쭉한 그래프가 됨 (반대는 뚠뚠한 그래프)
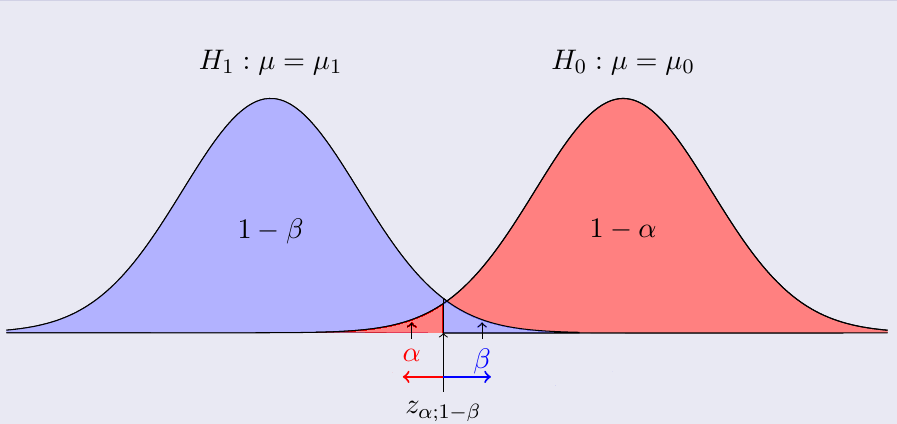
- 같은 데이터와 표준오차를 가짐으로 (
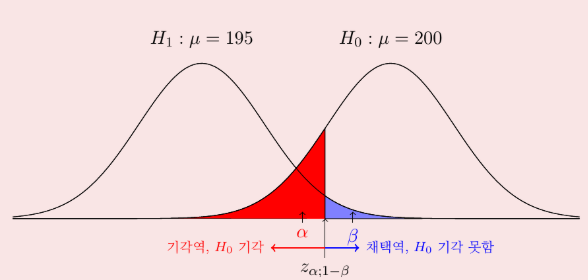
를 크게하면 가 작아짐
를 작게하면 가 커짐
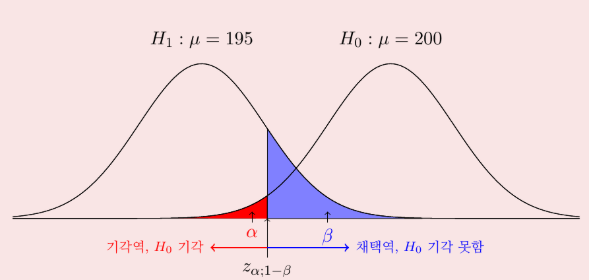
- 위의 그림처럼 우리가 긋는
가 어느정도인지 예상할 수가 없음 는 정해진 값이므로, 데이터의 개수를 늘려, 에 대한 값을 줄이는 방법이 있음
- 제한된 표본에 의한 가설이므로,
- p-value가 말해주지 않는것
- 데이터가 무한히 많아지면, 아주 미세한 평균차이도 p-value는 0이 되버림
- 어떤 다이어트약이 1년동안 평균 0.0001kg 빠졌다. -> 데이터가 무한히 많아, 아주아주 유의미함이라고 나오게됨
- 하지만 0.0001kg 을 위해 돈을 지불하는 사람은 없을것임
- 효과 크기
- 변동성에 비해 얼마나 큰 차이인지 서술해주어, 가성비를 따질 수 있게함
- 효과 크기안에 평균이 존재하는데, 평균의 차이가
에 영향을 주므로 평균의 차이를 아는것이 어느정도 변화를 잡아낼 수 있는지에 아주 중요하다고 볼 수 있음 - 평균의 차이가 작아지면
가 커짐
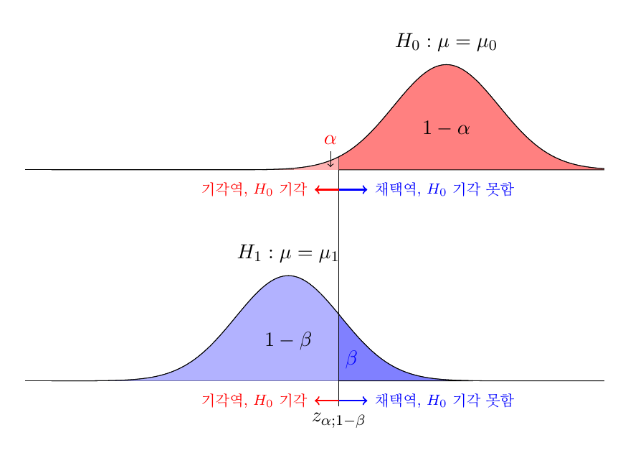
- 평균의 차이가 커지면
가 커짐
- 결론
- 평균의 차이가
의 크기를 알려주기 때문에, 해당 정보를 이용해 검정의 효과를 예측할 수 있음
- 평균의 차이가
- 데이터가 무한히 많아지면, 아주 미세한 평균차이도 p-value는 0이 되버림
가설검정 세팅
- 위에서 언급한대로
에 따라 전략에 대한 이해를 달리할 수 있음 - 이 전략은 5% 이상의 수익 차이는 확실히 잡아낼 수 있는 세팅이었는데(낮은
), 결과가 안 나왔으니 진짜 5% 수익은 안 나는 게 맞구나. - 이 세팅은 1% 수익 차이는 거의 못 잡는 세팅이었네(
가 너무 높음). 결과가 안 나왔다고 해서 1% 수익 전략이 아니라고 단정할 순 없겠어."
- 이 전략은 5% 이상의 수익 차이는 확실히 잡아낼 수 있는 세팅이었는데(낮은
- MDE (Minimum Detectable Effect) 결정
- MDE: 내가 잡고싶은 최소한의 차이
- 예) 수익률 2%가 유의미하게 나는지
- 0.1% -> 좁쌀일수록 큰 돋보기(n)필요
- 10% -> 코끼리일수록 작은 돋보기도 충분
- 예) 수익률 2%가 유의미하게 나는지
: (시장의) 변동성이 클수록 신호를 찾기 어려워 더 많은 데이터가 필요함 : 유의수준 5% 기준 1.96, 운을 실력이라고 착각하지 않을 엄격함의 정도 (1종오류확률) : 검정력 90%기준 1.28, 실력을 놓치지 않을 예리함의 정도 (2종오류확률)
- 예시
- 알고리즘 수익률 변동성(
)이 연간 15%(0.15) 정도라고 가정하고, 연간 수익률 차이 **2%(0.02)**를 90% 확률로 잡아내고 싶을때 데이터의 개수 - 분자 계산:
- 분모 나누기:
- 제곱하기:
- 분자 계산:
- 결과: 약 590개의 데이터가 필요
- 만약 이게 일간 수익률 데이터라면? 약 2.3년 치(590일)의 매매 데이터가 있어야 "내 전략이 시장보다 2% 높은 건 실력이다"라고 90% 확신하며 말할 수 있다는 뜻
- 알고리즘 수익률 변동성(