일원배치 분산분석(One-way ANOVA)
- 독립변수 하나 내에 비교해야 할 그룹이 3개 이상(A, B, C ...)이며 사용하는 방법
- t-검정을 여러번하면 오류 확률이 높아지기 때문에 한번에 비교하는 방식
배경지식
1종 오류의 본질
- 유의수준 0.05는 귀무가설이 맞았는데도 실수로 틀렸다고 할 확률(제1종 오류)를 5%까지는 봐주겠다는 약속과 같음
- 본질: t-검정 한번할때, 우리는 95%확률로 옳은 결정을 내리고 5%의 확률로 잘못된 결정을 내릴 위험을 감수함
- 신뢰 수준(1 -
): 0.95, 즉 내가 틀리지 않았을 확률
오류의 누적
- 위에서 언급한 내가 틀리지 않았을 확률: 0.95
- 세 번의 검정 모두에서 단 한번도 틀리지 않았을 확률:
- 적어도 한번은 틀릴확률:
즉 약 14.3% - -> t-검정을 반복할시, 통계적 왜곡이 발생함
ANOVA
- 신호 행렬이, 잡음 행렬보다 몇배나 큰가? 하는 것을 확인하는 기법
- 평균이 흩어진 정도가 데이터들이 흩어진 정도보다 유난히 크면, 평균이 다른것이다!
- 이 학생이 책읽은게 10개인 이유는, 우리학교가 읽는 정도(15)에서 해당 학급이 유난히 안읽고(-3), 그 개인도 유난히 안읽는(-2) 것이 합쳐진 결과이다.
- 이 질문을 일반화하여, 단순히 개인의 노력이나 나태때문에 평균이 다른것인지, 이 학급이 다른건지 확인하겠다는것
- 그 다름이 F-값 -> 최종판정은 p-value
- 등분산성이 깨지면 분모가 왜곡됨
- 관측값 = 전체 평균 + 처리 편차 + 잔차
- 학생의 점수 = 모든 학생의 평균 + 그 반만의 특성 + 학생 개인의 개성

- 학생의 점수 = 모든 학생의 평균 + 그 반만의 특성 + 학생 개인의 개성
- 전체 평균 행렬 : 우리 학교학생은 기본 이정도해, 라는 baseline
- 총 제곱합과 관련
- 학급별 평균 차이 행렬 : ANOVA가 궁금해하는 신호, 1반은 평균보다 3권 적게 읽음, 2반은 2권 더 읽음
- -> 학급의 영향력만 발라낸 것
- -> 처리제곱합과 관련
- 학급 안에서의 평균 차이 행렬 (잔차):
- 잡음, 학급과 상관없는 개인차
- 잔차제곱합과 관련
- 아래와 같은 수식을 따름
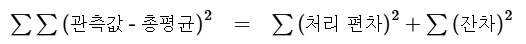
귀무가설
- 귀무가설 (
): : "모든 학급의 평균 독서량은 사실상 다 똑같다." - 대립가설 (
): 적어도 하나의 가 다르다. - "최소한 어느 한 학급은 평균 독서량이 다르다."
일원배치 분산분석
전제조건
- 독립성: 각 집단에 속한 사람과 데이터는 아무런 관계가 없어야함 (한사람이 두번 답하거나 그러면 안됨)
- 정규성: 각 집단의 데이터는 정규분포를 따라야함 (표본 수가 적으면 Shapiro-Wilk 검정 등으로 확인)
- 등분산성: 모든 집단의 분산이 비슷해야함
- Levene의 검정을 해서 p > 0.05가 나와야 분산이 같다고 인정받음
F-값
- Step 1: 제곱합(SS, Sum of Squares) 구하기
(집단 간 제곱합): 각 집단의 평균이 전체 평균으로부터 얼마나 떨어져 있는가? (신호) (집단 내 제곱합): 같은 그룹 안에서 개별 데이터들이 그룹 평균으로부터 얼마나 떨어져 있는가? (잡음) (전체 제곱합): - 모든 개별 데이터가 '전체 평균'에서 얼마나 떨어져 있는지 제곱해서 합친 것입니다.
- Step 2: 자유도(df) 결정하기
- 제곱합(SS)들은 개수가 많아질 수록 커지기 때문에 평균적인 변동으로 변경
: (집단 수 ) - 1 : (전체 데이터 수 ) - (집단 수 )
- Step 3: 평균제곱(MS, Mean Square) 계산
- 제곱합을 자유도로 나누어 '평균적인 변동량'을 구함
- Step 4: F-값 도출
- 분자가 커질수록 뚱딴지 같이 전체 평균에서 크게 떨어진 집합이 있는것 -> "적어도 한 집단은 평균이 다르다" -> 귀무가설기각
- 추가:
에타제곱: 샘플수가 많으면 미세한 차이도 p < 0.05가 나올 수 있음 = 을 기반으로 "학급의 차이"가 설명하는 지분이 얼마인지 확인해야함
사후분석
- ANOVA로 다르다는 판정을 내리면, 사후분석을 통해 범인을 찾아함
- Tukey(튜키) HSD: 가장 많이 쓰이며, 모든 집단을 1:1로 다 비교
- 낱개 검정의 유의수준을 0.05보다 훨씬 작게 강제로 깎고, 곱확률이 0.05가 되게 맞춤
- Bonferroni(본페로니): 매우 엄격해서 보수적인 결론을 내릴 때 사용
- Scheffe(셰페): 집단 간 샘플 수가 다를 때 유용