다중선형 회귀분석 (multiple linear regression analysis)
배경지식
행렬
행렬의 곱
-
- 앞에 놈의 행을 로 훑고, 뒤에 놈의 열을 로 훑어서 곱한다.
전치 행렬
- 혹은 와 같이 표현
- -> 로 바꾸게됨
- 행렬로 볼 경우, 왼쪽 위에서 시작하는 대각선을 축으로 데이터를 전부 대칭이동을 했다고 생각가능
벡터의 제곱합
- 와 같이 표현가능
- a' : [a1, a2, ..., an] (가로)
- a : [a1, a2, ..., an] (세로)
- a'a :
- cf) 행렬일 경우
- 처럼 표현가능
- 각 원소의 내용 는 와 같이 표현이 됨
- 로 표현가능 (는 와 같음)
- i = j 일때는,
- i != j 일때는,
- i열과 j열의 데이터를 곱하여 더함 -> i열과 j열의 공분산과 비슷함
- 후술할 T 행렬을 통과했다면, n-1로나누면 그게 공분산 행렬임
역행렬
- 과 같이 표현하고, 곱해서 단위행렬(대각선만 1인)이 되는 행렬
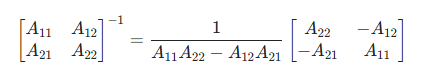
T 행렬
- 중심화 행렬
-
- J 행렬은 모든 원소가 1인 행렬
- Jy 를 구하게 되면 (벡터일때), 각 원소가 모두 로 벡터 원소의 합이 됨
- 1/n 을 이때 곱해주게되면, 모든 원소가 가 됨 (즉 평균의 벡터)
- Iy 에서 이를 빼주면, 즉 모든 원소가 편차가 되게됨
- 이는 기존 벡터에서 평균을 빼주게 되므로, 벡터의 차의 성질에 의해 시작점이 평균이되고 크기는 편차인 그런 벡터로 변함
- cf) 벡터를 평균 벡터의 수직 보공간(Orthogonal Complement)으로 투영시킨다. "평균이라는 성분"을 가위로 싹둑 잘라내 버리는 행위.
- T는 대칭이다. (T의 수식 참조)
- T는 멱등이다. (평균이 0 일테니)
양말과 신발의 법칙
- 원래는 양말을 신고(A) -> 신발을 신음(B)
- 되돌리려면 신발을 벗고, 양말을 벗음
- 선형변환으로 바꾸면 그대로 적용이 됨
벡터/행렬의 미분
| 형태 (Scalar q) |
미분 대상 |
결과 () |
비유 (숫자 미분과 비교) |
|
|
|
|
|
|
|
|
|
|
(단, 는 대칭) |
|
다중선형 회귀분석
- 복잡한 관계를 수식과 숫자로 요약가능하게함
- 삼성전자 주가()에 영향을 주는 요인이 환율(), 금리(), 반도체가격()라고 하자
- 환률이 1%오를 때 주가는 몇 % 변할까?
- 금리와 환율 중 주가에 더 치명적인 것은 뭘까?
- 종속변수 와 개의 독립변수 존재(상수항 제외)
-
- 를 n개로 확장시,
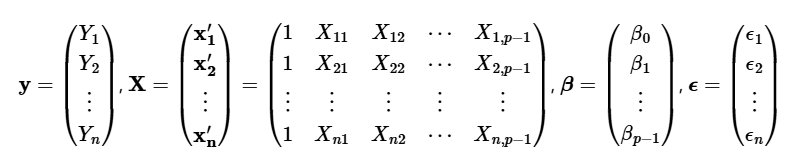
F-value 의 유도
- SST와 SSR과 SSE의 관계를 나타내면 아래와 같음
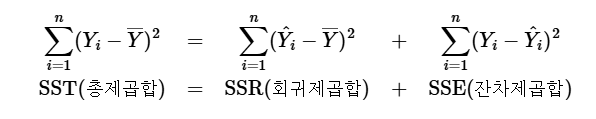
잔차를 최소화하는 최소제곱법
- 잔차는 실제값(y)와 예측값 (Xb)의 차이임
- 양말 법칙을 이용해 유도하면
- 와 는 계산해보면 같은 스케일러라 두개를 합침
- 위에서 구한 잔자제곱합을 최소화하기 위해 b로 미분을 진행
- y'y 는 상수, -2X'y, 2X'Xb (2차항이라 2가 튀어나옴)
- 즉,
- cf) 수식을 다시 쓰면 , 즉
- 오차가 최소화가 될때, 에러는 우리가 가진 데이터(평면)와 수직이다.
- 그러면 X라는 평면위에서 가 성립함
- 통계적으로는 (전체 변동 ) = (모델이 설명한 변동 ) + (오차 변동 ) 이됨
- 이게 무슨말이야!
- X는 p차원 평면임, y는 그 공간위에 떠있는 점임, 이때 원점에서 그점까지 이어, 하나의 벡터를 간주함
- 그리고 그 선를 X에 투영시킬때 벡터 가중치 를 사용함, 그 투영된 선을 라고 함
- 우리가 원하는 것은 오차를 최소화 하며 투영을 하는 를 찾는것
- 오차란 무엇이냐? 오차는 y와 를 통해 투영된 의 끝점 끼리의 거리임
- 오차를 최소화하려면, 평면에 수직하게 y를 투영해야함, 그것을 만들어주는 를 찾는것임
- Xb 를 해서, 그 벡터()를 찾는것임, 그 벡터와 e가 수직하는 순간, 그때의 e는 최소화 된다.
- 아무튼, 리마인드
Hat Matrix
- 우리의 예측값
- 위에서 구한 수식을 대입
- y를 예측값으로 바꾸어주니, 를 hat matrix(H)라고 부름
SST의 정리
- 총제곱합은 아래와 같이 정리 가능 ( 를 이용)
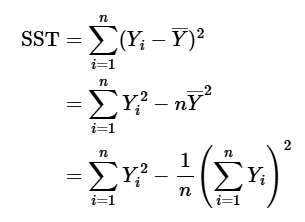
- 와 그의 제곱합을 행렬로 표현하면
- 추가로
- SST에 대입을 하면
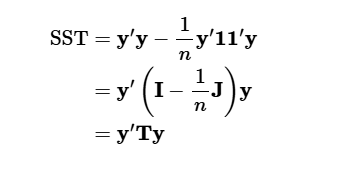
- 결론:
SSR의 정리
- b는 hat beta 즉 의 추정값 를 의미함
- 우리가 정의한 다중선형회귀식에서
- , 하나의 예측 벡터의 합은 종속행렬과 회귀계수 벡터의 곱
- , 제곱의 합은 벡터의 전치행렬의 곱으로 표현이되고 이를 풀면 마지막 항과 같이 유도가능
- 에서
- 또한
- SSR은 아래와 같이 표현가능
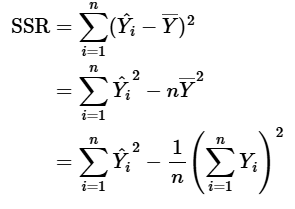
-
- 를 대입하고 뒤집기를하면
-
-
-
- H (예측 배열) - 1/n J 평균배열() 를 하니, 회귀다! (회귀 제곱합)
-
- R은 Regression: 정답에 가까우면 커지는 값 (평균에서 멀어짐, 모델이 의미 있어짐)
- R은 모델의 성적표라고 볼 수 있음
SSE의 정리
- 이전에 설명한것은 빼고 빠르게 진행
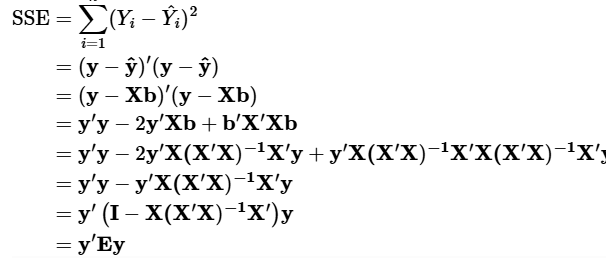
- 잔차는 I - H 이라고 볼 수 있음 (아래서 두번째 equation)
- y라는 실제 데이터에 I - H 를 곱하니 오차가 등장함 -> 오차행렬
정리
| 필터 이름 |
수식 |
하는 일 (역할) |
결과물 |
| 정답 필터 () |
|
아무것도 안 하고 그대로 통과 |
(실제값) |
| 예측 필터 () |
|
평면 위로 내리꽂아 그림자 생성 |
(예측값) |
| 오차 필터 () |
|
정답에서 예측된 성분만 제거 |
(순수 오차) |
분산분석표
- 자유도를 나누어 F-value를 얻도록하자

F-value와 변수 선택
- 유의한 독립변수를 추가할때 사진과 같은 방식 사용
- X를 많이 추가하면 e가 최소화 되긴함, 하지만 오버피팅의 가능성이 있으므로, F-value가 유의하게 만드는 X만 추가하여 모델의 퀄리티를 올리기 위함
