연속확률분포(continuous probability distribution)
- 확률분포
- 확률변수(수치화된 사건)에 대해 확률을 내뱉는 함수
- 연속확률분포
- 확률변수 X가 가질 수 있는값이 무한개이며 셀 수 없는 경우 (ex 실수)
- 연속확률분포가 내뱉는 확률에 대한 함수를 확률밀도함수라고 칭함
- 확률밀도함수의 조건
- 모든 x값에 대해
- 연속확률변수에서 특정 x에서의 확률은
- 키가 175cm 일 확률 -> 수학적으로는 175.0000....cm 일 확률
- 175.000000001 이거나, 174,9999999 일 수 있음
- 가능한 가짓수가 무한대이기 때문에, 특정 숫자를 맞출 확률은
- 그렇기 때문에 등호도 무의미함
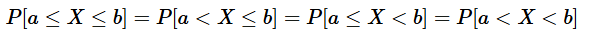
- 모든 x값에 대해
- Goal
- 정확한 수식의 유도보다는 배경지식 및 어떤 상황에서 어떤 분포를 써야하는지 결정하기 위해 정리
정규분포
- 복잡한 수식보다는 모양와 파라미터에 집중, 복잡한 수식은 필요할때 서치 및 적용 예정
- 일반적인 데이터가 따르는 종 모양의 분포를 정규분포라고함
- 사람들의 키의 분포
- 센서 데이터의 노이즈의 분포
- 두가지 파라미터가 존재함
- 평균(
, 위치모수): 종의 '꼭대기'가 어디 있는지를 결정 - 평균이 커지면 그래프가 오른쪽으로 통째로 이사감, 작아지면 왼쪽으로 이동
- 표준편차(
, 크기모수): 종의 '너비'를 결정합니다. - 평균으로부터 얼마나 데이터들이 떨어져 있는가?
가 크면(많이떨어져있음): 그래프가 옆으로 퍼지고 낮아집니다. (데이터가 들쭉날쭉함) 가 작으면(뭉쳐있음): 그래프가 뾰족해지고 평균 근처에 몰립니다. (데이터가 일정함)
- 평균(
- 특징
- 좌우분포
- 면적은 1
- 매직 넘버 (68, 95, 99.7)
- 평균에서
안에 데이터의 68%가 들어있습음 - 평균에서
안에 데이터의 95%가 들어있음. (보통 여기에 안들어오면 '특이치'라고 판단) - 평균에서
안에 거의 모든 데이터(99.7%)가 들어옴
- 평균에서
으로 표현
표준정규분포
- 확률 변수 X가 정규분포를 따를때, 평균이 0이고, 분산이 1인 정규분포로 변환하는 것을 표준화라고 하고, 이를 표준 정규분포 Z라고 함
, 데이터에서 평균을 빼고 표준편차로 나눔
t-분포
- 정규분포가 세상의 모든것을 다 알때 사용할 수 있는 분포라면, t-분포는 표본이 적어서 오차범위를 넉넉하게 잡은 분포
- 현실 세계에서 모집단의 평균과 표준편차를 알 확률은 0%에 가까움
- 불확실성 때문에 정규분포(Z)를 사용하면 실제보다 확률을 과신하게됨, 그래서 양 끝(tail)을 더 두툼하게 만든 t 분포를 사용
- 다음과 같은 상황에서 t-분포를 사용함
- 표본의 크기(
)가 너무 작을 때 (보통 30개 미만) - 모집단의 정보(
)를 모를 때
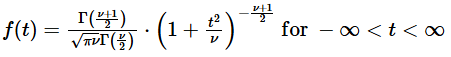
- 표본의 크기(
- 현실 세계에서 모집단의 평균과 표준편차를 알 확률은 0%에 가까움
자유도
- t-분포는 평균이나 분산대신 자유도(
)라는 단 하나의 값에 의해 모양이 결정됨 (표본 개수 - 1)로 계산함
- 자유도가 작으면, 꼬리가 아주 두꺼워지고 납작해짐
- 자유도가 커지면, 표준정규분포와 가까워짐
t-test
![평균 비교] 참조
- t-value: t-test 는 데이터로부터 특정 수치를 계산함, 그를 t-value라고 함
- ex) 단일 표본 검정:
- t-value는 인정할 수 있는 오차에 비해 우리가 발견한 차이가 얼마나 큰가? 를 나타내는 점수
- ex) 단일 표본 검정:
- 앞서 언급한 f(t)는 귀무가설일때, 이런 t값이 얼마나 자주 나올까의 확률의 그래프임
- t-value를 f(t)에 대입하여, 그 지점의 높이가 어디인지 확인
- 중앙에 있을 수록, 귀무가설 채택
- 꼬리에 있을 수록, 차이가 진짜 있구나라고 주장할 수 있음
- 그 지점의 높이에서 꼬리까지의 면적이 p-value
- t-value를 f(t)에 대입하여, 그 지점의 높이가 어디인지 확인
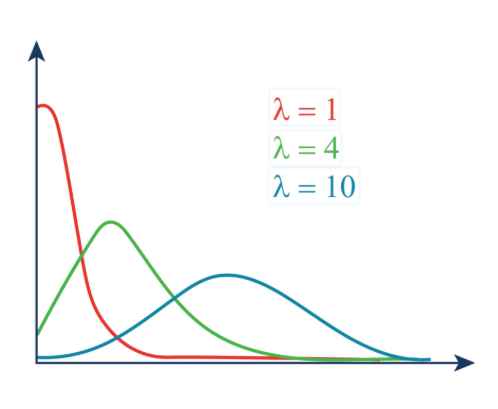
카이제곱분포
- 여러 독립적인 요인을 합쳐서 설명하기 위한 분포
- 표준정규분포의 데이터를 제곱해서 더한 분포
- 표준정규분포를 따르는 데이터 하나를 뽑아서 제곱(
) - 이 제곱된 값들을 k개 더함 (
) - 이렇게 더해서 나온 숫자들이 그리는 분포가 자유도가 k인 카이제곱 분포
- 합계에 관한 고찰
- 확률 변수를 더하는 것
- 주사위를 던졌을때의 확률변수
{1, 2, 3, 4, 5, 6} 전부 1/6 - 주사위 두개를 던졌을때의 확률 변수
- {1,2,3,4,...,12} 경우의 수가 늘어나고, 확률도 1/12, 여전히 모든 확률의 합은 1
- 고찰
- 확률변수를 더해도 여전히 확률 변수, 기댓값의 변화는 일어남
- 기댓값 = 자유도
- 주사위를 던졌을때의 확률변수
- 확률 변수를 더하는 것
- 카이제곱 분포의 경우, 양수의 합이므로, 기댓값또한 오른쪽으로 이동함
- k>30이면 정규분포 모양에 가까워지며 오른쪽으로 이동함
- 카이제곱분포의 쓰임새
- 여러 객체의 상호작용
을 더한것이니, 주사위의 예시처럼 다양한 경우의수를 확인가능 - 예를들어, 센서를 사용할때 X,Y,Z축의 센서의 노이즈가 정규분포를 각각 따른다고 가정
- 그렇다면 전체적인 시스템은
을 따르고, 이 값이 자유도가 3인 카이제곱 분포
- 적합도 검정
- 분산에 대한 가설을 세우면, 카이제곱 분포를 사용
- ex) 특정 행위를 했을때, 분산이 우연히 이렇게 튀었을 확률은 굉장히 낮다.
- 센서데이터가 정규분포를 따르는지 의심될때, 주사위가 사기인지 의심될때
- 예상값과 실제 관측값의 차이를 각각 제곱해서 더함
- 차이의 합이 카이제곱 분포의 꼬리부분에 가있다면, 우연이 아니라고 볼 수 있는것
- 정리하면, 모분산이 특정 값이라고 가정했을때, 표본 분산으로 검정하거나, 표본 분산으로 모분산을 추정하는데에 사용함
- 분산에 대한 가설을 세우면, 카이제곱 분포를 사용
- 여러 객체의 상호작용
- 표준정규분포를 따르는 데이터 하나를 뽑아서 제곱(
- 예시
- 적합도 검정: "이 게임, 조작 아냐?" (Gacha/Dice)
- 시나리오: 주사위를 60번 던져, 이론적으로는 1부터 6까지 각각 10번씩(기대치,
) 나와야 함 - 그런데 실제로는 1이 20번 나오고 6은 한 번도 안 나왔다면? "이 주사위 문제 있다!"라고 말할 근거를 말하기 위해 카이제곱 사용
에 대입해 모든 눈에 대해 계산하여 더 함 (관측된 오차의 제곱) - 합이 커질 수록 잘못된 주사위일 가능성이 커짐
- 시나리오: 주사위를 60번 던져, 이론적으로는 1부터 6까지 각각 10번씩(기대치,
- 동질성 검정: "커피 맛이 왜 이래?" (Consistency)
- 시나리오: 단골 카페의 커피 맛이 일정한지 보려고 함. 사장님은 "우리 기계는 오차 범위(분산,
)가 0.1로 아주 일정해요!"라고 주장. 직접 10잔을 마셔보고 변동성을 체크하는 것 에 대입 - 상황: 10잔(
)을 조사했더니 내가 계산한 분산( )이 0.5가 나왔고, 사장님 주장( )은 0.1임. - 대입:
- 해석: 자유도 9(
)인 카이제곱 표에서 45는 엄청나게 큰 숫자, 결론은 "사장님, 기계 점검하셔야겠는데요?"라고 말할 수 있음
- 시나리오: 단골 카페의 커피 맛이 일정한지 보려고 함. 사장님은 "우리 기계는 오차 범위(분산,
- 독립성 검정: "커피랑 코딩 실력이 상관있어?" (Relationship)
- 시나리오: 커피를 마시는 사람"과 "코딩 에러율" 사이에 관계가 있는지 궁금함. 그냥 '남남'인지(독립), 아니면 '상관이 있는지'를 표를 그려서 확인.
- 이것도
공식을 쓰지만, 다만 (기대값)를 구하는 방식이 다름 구분 에러 많음 에러 적음 합계 커피 마심 30 ( ) 10 40 안 마심 10 50 60 합계 40 60 100 - 기대값(
) 계산: 전체 100명 중 커피 마시는 사람 40%, 에러 많은 사람 40%라면, 둘이 상관없을 때 '커피 마시며 에러 많은 사람'은 명이어야 함 (확률의 곱) - 대입: 실제 관측치는 30명(
), 기대치는 16명( ) - 해석: 이런 식으로 칸마다 계산해서 더합니다. 값이 크면 "커피와 에러율은 서로 남남이 아니다(관계가 있다)!"라고 결론 냄
- 귀무가설이 채택되지 않은것 (둘이 상관없지 않음)
- 적합도 검정: "이 게임, 조작 아냐?" (Gacha/Dice)
연속확률분포 중간정리
- 우리는 모분산을 모르고 알기도 매우힘들다
- 모분산을 약분해서 없앤다.
- t-분포, F-분포
- 모분산을 추정하거나 검정한다
분포
- 모분산을 약분해서 없앤다.
F분포
- 세 집단의 평균 비교에 사용
- 두 집단의 분산비율 추론에 사용 (한 집단의 분산 추론은
분포) - 두 집단의 분산을 각각의 자유도로 나눠, 그들의 비율을 보는것
- F의 값이 1에 가까우면, 두 집단의 분산(흔들림)이 비슷
- F값이 1보다 훨씬 크거나 작다면, 한쪽 집단이 다른 쪽보다 훨씬 더 심하게 널뛰고 있음
- 두 집단의 분산이 같다고 가정하면, 모분산이 서로 약분되어 두 집단을 비교할 수 있게됨
- 주요 특징
- 제곱의 합을 나눈것이니 음수가 나올 수 없음 (
) - 비대칭형, 오른쪽으로 꼬리가 김
- 분자의 자유도와 분모의 자유도에 의해 모양이 결정됨
- 분모와 분자의 위치를 바꾸어 역수 취할 수 있음 (A/B를 비교하는것 = B/A를 비하는것)
- 제곱의 합을 나눈것이니 음수가 나올 수 없음 (
- 예시
- 세 집단의 평균 비교
- F-값 생성
- 분자 (집단 간 변동, Signal): 구글, 엔비디아, 테슬라 각 그룹의 평균들끼리 얼마나 떨어져 있는지 봅니다. 테슬라의 수익률만 저 멀리 가 있다면 이 값이 엄청나게 커짐
- 분모 (집단 내 변동, Noise): 각 종목의 일일 수익률이 자기네 평균 주변에서 얼마나 지저분하게(변동성) 움직이는지 봄
- F-값 계산:
- 일반적인 주가 변동보다 테슬라 수익률만 이상하게 다르다는 결론
- F-값 생성
- 두 집단의 분산비율 추론
- F-값 생성
- 구글은 얌전한데, 테슬라는 너무 널뛴다는 것을 검증하고 싶음
- 두 집단의 표본 분산의 비율을 직접구함
- F-값 계산
- 계산:
- 가정: "두 종목의 위험(모분산)은 원래 같다"고 가정!
- 계산:
- F-값 생성
- 세 집단의 평균 비교