다변량 정규분포와 선형회귀(multivariate analysis)
다변량 정규분포
- 두개 이상의 정보를 세트로 묶어서 보고 싶을때 쓰는 정규분포
- 키가 190cm인데 몸무게가 40kg 사람은 얼마나 많을까?
- 여러 변수
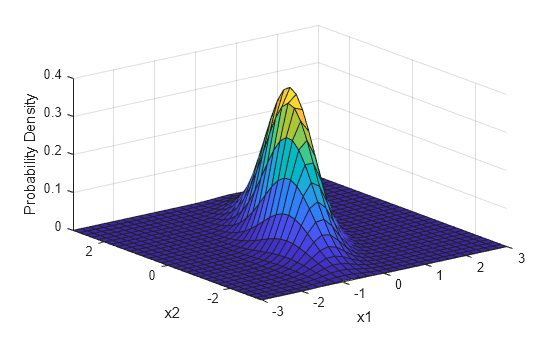
을 묶은 벡터가 있을 때, 이들의 결합 확률 분포가 다차원 종 모양을 그릴때 다변량 정규분포를 따른다고함
- 모양에 따른 의미
| 모양 | 의미 | 데이터의 특징 |
|---|---|---|
| 완전한 원 | 독립적 | 두 변수가 아무 상관 없음 (예: 내 시력과 내 통장 잔고) |
| 기울어진 타원 | 상관관계 있음 | 하나가 커지면 다른 하나도 커짐/작아짐 (예: 키와 몸무게) |
| 아주 얇은 타원 | 강한 결합 | 하나를 알면 다른 하나를 거의 확실히 맞출 수 있음 (예: 섭씨와 화씨 온도) |
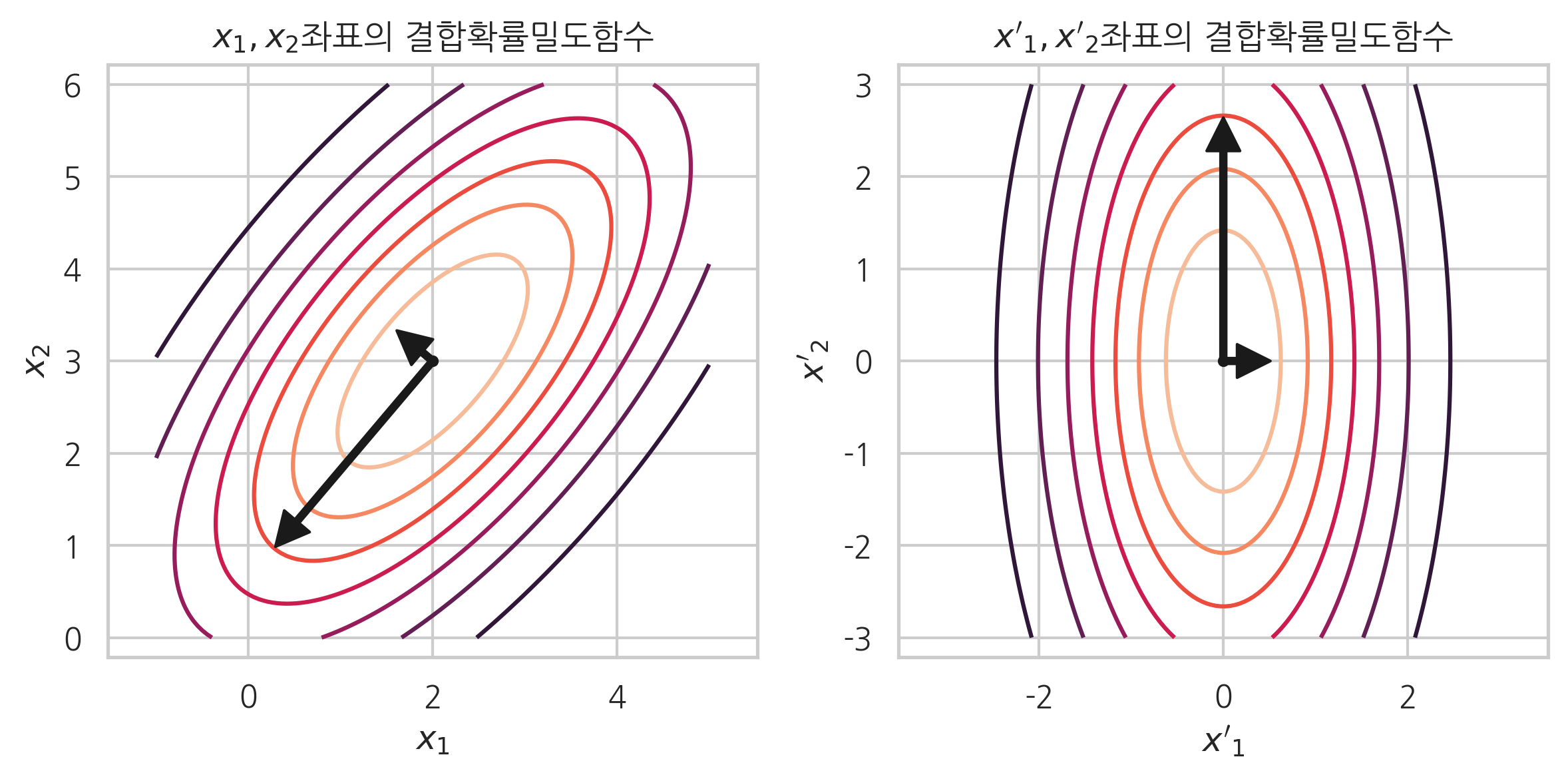
- 왼쪽 그림: 변수 1이 커지면, 변수 2도 커지는 경향
- 오른쪽 그림: 변수 1과 변수 2가 독립적임
[1차원 정규분포 식]
[다변량 정규분포 식 (k차원)]
-
평균 벡터(
) : 각 변수의 중심점. 예를들어 [무릎 각도, 각속도]라면 각각의 평균값이 들어있는 리스트 -
공분산 행렬 (
또는 ): 분포가 어느 방향으로 얼마나 퍼져 있는지를 나타내는 행렬 - 행렬의 대각선 값: 각 변수들의 개별적인 불확실성(분산)
- 나머지 값: 변수들끼리 같이 움직이는 정도(공분산)
- 이 값이 0이 아니면 분포가 대각선 방향으로 기울어진 타원형이 됨 $$\boldsymbol{\Sigma} = \begin{bmatrix} \text{Var}(x_1) & \text{Cov}(x_1, x_2) \ \text{Cov}(x_2, x_1) & \text{Var}(x_2) \end{bmatrix} = \begin{bmatrix} \sigma_1^2 & \sigma_{12} \ \sigma_{21} & \sigma_2^2 \end{bmatrix}$$
- 공분산 :
- 두 데이터의 평균에서의 거리의 곱의 평균
- 같은 방향으로 움직이면 양수가 쌓임, 다른 방향으로 움직이면 음수가 쌓임
- 단위에 너무 민감하다는 단점이 있음
- -> 표준편자로 나누어 -1에서 1로 정규화하는것이 상관관계 계수
- 공분산 :
- 이 값이 0이 아니면 분포가 대각선 방향으로 기울어진 타원형이 됨 $$\boldsymbol{\Sigma} = \begin{bmatrix} \text{Var}(x_1) & \text{Cov}(x_1, x_2) \ \text{Cov}(x_2, x_1) & \text{Var}(x_2) \end{bmatrix} = \begin{bmatrix} \sigma_1^2 & \sigma_{12} \ \sigma_{21} & \sigma_2^2 \end{bmatrix}$$
-
지수 부분
: 마할라노비스 거리(Mahalanobis Distance) - 공분산 수식 참조
: 각 데이터가 퍼져있는 분산과 공분산 만큼 나어주는 것 - 변수마다 scale이 다르기 때문, 키의 경우 10cm씩, 시력의 경우 0.1씩 변함
- 해당 scale을 나누어주어, 평균에서의 거리보고 싶은것
- 평균에서의 벡터의 제곱 -> 거리
- 데이터의 퍼진 정도의 크기를 무시하고 평균에서의 거리를 도출는 수식 (퍼진 정도 자체는 유지됨)
- 공분산 수식 참조
-
전체 식의 의미
- 지수부, 즉 거리가 클 수록, f(x)의 크기는 지수적으로 작아짐 -> 거리가 멀 수록 그럴 확률이 낮다는것을 내포
- 종 모양을 만드는 역할
- 173cm, 70kg 은 엄청나게 많은 데이터
- 190cm, 40kg 은 적은 데이터
- 종 모양을 만드는 역할
- 분모부, 전체 확률의 합을 1로 만들어주는 역할
- 지수부, 즉 거리가 클 수록, f(x)의 크기는 지수적으로 작아짐 -> 거리가 멀 수록 그럴 확률이 낮다는것을 내포
-
단면별 해석
- 세로 단면으로 잘랐을때
- x1 or x2를 고정하고 자르는것, 단면이 정규분포가 나옴
- 단, 확률의 합이 1은 아님
- 하지만 조건부 확률로 다시 넓이가 1이 되게 만드는 식으로 통계적용
- ex) 키가 190cm일때 몸무게의 정규분포
- ex) 몸무게가 70kg일때 키의 정규분포
- 단, 확률의 합이 1은 아님
- x1 or x2를 고정하고 자르는것, 단면이 정규분포가 나옴
- 가로로 잘랐을때
- 타원이 나옴
- 타원 방정식:
로 가정할때, 벡터에 대한 수식은 아래와 같이 풀림 - 분산이 타원의 찌그러진 정도를 결정함을 알 수 있음
- 분산이 같으면 원이 됨
- 공분산이 타원의 기울기를 결정하는 것을 알 수 있음 (xy의 계수)
- 0에서 멀어질수록 기울기가 생긴다고 볼 수 있음
- 분산이 타원의 찌그러진 정도를 결정함을 알 수 있음
- 타원 방정식:
- 타원이 나옴
- 타원의 밀도
- 먼저, 다변량 정규분포는 동심타원 여러개가 z축에 대해 지름이 다르게 존재하는 형태
- 타원의 밀도는 상관관계 계수와 관련있음
- 상관관계 계수가 1에 가까울 수록 바늘처럼 가늘어짐
- 즉 기울기와는 무관함
- 상관관계 계수가 1이면, x1이 결정되면 x2도 결정이 되므로 (확률분포로 존재하는 것이 아님), 실선에 가깝게 다가감
- 상관관계 계수가 1에 가까울 수록 바늘처럼 가늘어짐
- 세로 단면으로 잘랐을때
선형회귀
- 질문
- x1 = 키, x2 몸무게, 다변량 정규분포 존재
- x1이 190일때, x2는 얼마라고 하는게 제일 좋을까?
- -> x1 = 190 일때 자른 단면(정규분포)의 꼭대기값 (즉 x2의 평균값)
- 선형회귀
- 모든 x1 에 대해 x2의 꼭대기값을 이은 선분이 선형회귀에서 찾는 정답
- 정보(X)가 주어졌을때, 궁금한 숫자(Y)를 가장 정확하게 맞히기 위한 알고리즘
- 연속된 숫자를 맞추는 것이 목표
- 가정
- X, Y가 직선으로 설명이 가능함
- 오차가 정규분포를 따름
선형회귀의 종류
다변량 정규분포를 모르고 데이터만 잔뜩있을때 선형회귀 정답을 어떻게 찾을 것인가?
- 최소제곱법(OLS): "직선과 점들 사이의 거리를 최소로 만들자!" (공학적 접근)
- 최대우도추정(MLE): "이 점들이 나올 확률이 가장 높은 모래성 모양을 찾자!" (통계적 접근)
선형회귀의 가정
| 구분 | 대상 | 의미 | 선형 회귀에서의 역할 |
|---|---|---|---|
| 각각 정규분포 | 개별 변수 | 각자의 분포만 예쁨 | 큰 의미 없음 |
| 다변량 정규분포 | 변수들의 조합 | 전체 구조가 예쁜 3차원 종 모양 | 선형 회귀가 완벽하게 작동하는 이상적인 상태 |
| 오차 정규분포 | 예측의 틀린 정도 | 직선 주변의 구름만 예쁨 | 실제로 모델을 돌리기 위해 꼭 필요한 조건 |
- 오차가 정규분포로 가정하는 이유
- 중심한계정리: 실제로 세상의 노이즈가 그렇게 돌아가기 때문
- 수학적 검증: OLS로 찾은 직선들과 점 사이의 거리가 최소가 되는 것이, 나타날 확률이 최대화가 되는것이 같아지기 때문 (OLS = MLE)
수학적 검증
- 우리가 구하려는 직선을
라고 가정 : 오차를 왼쪽과 같이 가정 가능 : 오차의 확률 밀도함수는 왼쪽과 같음 에서 z -> e로, u -> 0으로
- 데이터가
개 있다면, 이 모든 데이터가 동시에 나타날 전체 확률(우도, )은 각 데이터 확률을 모두 곱한 것
- 데이터가
- 결론: "확률 최대화 = 오차 최소화"
- 이제 식을 정리해 봅시다. 우리가 찾는
와 의 입장에서 보면, 앞부분의 은 상수일 뿐입니다. 중요한 건 뒷부분이죠.
- 이제 식을 정리해 봅시다. 우리가 찾는
- 이유 :
- 전체 값(
- 그렇다면 마이너스(
-
- 정리
- MLE의 목표:
(확률)을 크게 만들자! - 수학적 결과: 그러려면
(거리의 제곱)을 작게 만들어야 하네? - OLS의 목표:
을 작게 만들자! - 두개가 같은 목표가 된다!
- MLE의 목표:
- 오차가 정규분포가 아닐때
- OLS로 그은 선이 확률적으로 가장 그럴듯한 선이 아니게됨
- 선형회귀로 찾은 선의 주변에 점들이 몰려있지 않을때
- 물론 써도 되긴하지만, 선형적으로 데이터를 설명하기가 힘든 경우일 가능성이 높음
- OLS로 그은 선이 확률적으로 가장 그럴듯한 선이 아니게됨
오차 함수
- 데이터들의 분포는 의미가 있을 수도 없을 수도 있음
- 그 데이터 분포위에 알맞는 선을 그어줄 수 있게, 선의 모양을 결정해주는것이 오차함수
선형회귀의 오차함수
- 선형회귀에서 원하는 것은 연속된 다음 데이터를 가장 높은 확률이 되게 추측하는것
- 아래와 같이 상황별 오차함수를 정의할 수 있음
- MSE: 오차를 정규분포로 예상할때
- MAE: 오차를 라플라스 분포로 예상할때 (아웃라이어가 툭 튈때)
- 기하학적의미
- MSE와 MAE가 convex한 그래프를 내려간다는 것을 널리 알려진 사실임
- w와 b를 정함
- x를 정함 -> 데이터들의 평균적인 y위치가 나옴, 내가 예측한
가 나옴 - 두개의 차이가 크다?
- MSE는 민감하게 반응해서 w와 b를 크게 변경하여 최소 loss를 보이는 w와 b를 찾아감
- 볼록한 정도가 크다고 볼 수 있음
- 멀면 더 가파르게 옴
- MAE는 아웃라이어를 고려하기 때문에 둔감하게 반응하여 w와 b가 크지 않게 최소 loss를 보이게 찾아감
- 볼록한 정도가 작음
- 멀리 있든 가까이 있든 일정하게 바꿔나감
- MSE는 민감하게 반응해서 w와 b를 크게 변경하여 최소 loss를 보이는 w와 b를 찾아감
- 모든 x에대해 반복 (사실 행렬로 병렬)
- 가장 낮은 w와 b를 찾아감
- 경사하강법으로!
- x를 정함 -> 데이터들의 평균적인 y위치가 나옴, 내가 예측한
- 그러면 우리가 결론적으로 얻는것은, 데이터 분포에 오차함수의 의도에 맞게 선을 하나 긋는것
- MSE가 그은 선은 정규분포를 가정한, 점이 많은 곳을 잇는선
- MAE가 그은 선은 점들의 분포의 중앙에 긋는 선
딥러닝에서의 오차함수
- 딥러닝에서도 특정 데이터들이 있는데, 마찬가지로 내가 원하는 어떤 선을 긋는것
- 분류, 회귀를 위해 선을 그을 수 있음, 그 종류를 선택하는게 또 오차함수다
- 고양이와 강아지를 구분하는 선
- 주가를 따라가는 선
- 단, 오차함수가 convex하지 않기 때문에, 오차함수가 선형회귀보다 복잡하고 어려움
- local minimum에 빠지지 않게 주의해야함
경사하강법
- w나 b를 업데이트 할때, 미분을 진행, 그리고 학습률을 곱해서 그 방향으로 조금 이동
-> 경사 방향으로 w가 이동하게됨, convex한 그래프를 생각하면 loss가 가장 작아지는 w와 b로 이동하는 것으로 이해가능 - 너무 작은 값은 리소스를 너무 많이먹고, 너무 큰 값은 수렴하지 않으니 주의